Git (proof-of-concept): https://github.com/elegantwist/hierarchy_pandas
For processing reference information using pandas tables, in most cases, it is impossible to do without implementation of elements hierarchy (groups, subgroups, sub-elements).
There are two approaches for implementation of hierarchy in the tables: 1. Building n-tier indexes by means of pandas itself (in newer versions) and 2. Building a text string, where a single string composed of pointers to groups separated by a special character, specifies a full path to the item. The following describes a third approach that takes a bit from the first and second approaches, and has its weaknesses and strengths, and in certain cases may be the only variant to be used:
1. Each element of the dictionary is assigned its own ID code generated according to a pre-agreed format. This ID contains coordinates of the element in the hierarchy.
2. The ID format looks like an integer in the form of XXXYYYZZZ. With that, the lower level records (elements) take three junior classes — ZZZ (000-999), subgroups take three medium classes — YYY (000000-999000), top-level groups take three senior classes — XXX (000000000-999000000).
Examples of interpretation:
an element with ID 10013098 has coordinates: element id — 098, subgroup id — 013, id — 010
an element with ID 100 has coordinates: element id — 100, subgroup id — 000, id — 000
an
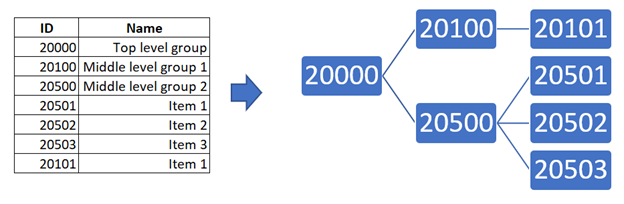
3. At the same time, this approach means that one should know in advance the maximum depth of the tree and fix the maximum number of elements in the tree. Accordingly, the maximum depth is the number of classes and the maximum number of elements – the number of orders in the group.
Thus, the composition and codes size ratio may vary (may be XYZ, XXYYZZ, XXXXYYYYZZZZ, … etc.), but the format should be uniform and to be chosen once, during tree markup
Thus, this approach is applicable only in the case when the hierarchy is not rebuilt dynamically online, but there is some time for relabeling.
With that, if ID assignment to the elements and groups is implemented in the specified logics, further tree navigation and selection of items will be performed as quickly as possible, because only the basic low-level filters and basic integer arithmetics are used, without slow searching for values in the substring and re-indexations.
Examples of implementation:
1. To select all elements in the group, for an incoming group ID it is sufficient to select all elements with IDs from XXXYYY000 to XXXYYY999
Example (for the XXYYZZ format):
For group 20500, IDs of all child elements will be in the range between 20500 and 20599
For group 130000, IDs of all child elements will be in the range between 130000 and 130099
With the use of pandas, it seems simple enough:
all_items = df[df.eval("(index >= 20500) & (index <= 20599)")]
2. To select all low-level subcategories by the ID of the top level group, just select all elements with ID from XXX000000 to XXX9999999, with the additional condition that the ID is evenly divisible by the group size, i.e. 1000 (this is a definite sign of a group)
Examples (for the XXYYZZ format):
For group 20000, IDs of all child subgroups will be in the range between 20000 and 29900 (group size = 100)
Code:
all_subgroups = df[df.eval("(index >= 20000") & (index <= 29900) & ((index % 100) == 0)")]
But if you have to select all top-level groups, it will be the range between 000000 and 990000, with the group size = 10000:
all_top_groups = df[df.eval("(index >= 0") & (index <= 990000) & ((index % 10000) == 0)")]
3. Select all the elements in the top-level hierarchy for all child subgroups, but without subgroups themselves: XXX000000 – XXX999999 by subtracting the ID which are evenly divisible by the group size (1000)
Example (for the XXYYZZ format):
For group 20000, IDs of all child elements of all sub-groups without subgroups themselves will be in the range between 29999 and 29999 (group size = 100), excluding the elements with IDs 20000, 20100, 20200, … , 29900
Code:
all_subgroups = df[df.eval("(index >= 20000") & (index <= 29999) & ((index % 100) != 0)")]
Examples show that the advantages of the method consist in the fact that all these select queries in the hierarchy:
– are easy to implement and deploy,
– are user-friendly, and
– work quickly both at the level of SQL and at the level of Pandas.
Thus, with the existing constraints of the described approach, it has advantages and enough flexibility, which in proper context may outweigh the disadvantages.